AI is transforming industries by enabling faster decisions and deeper insights, but its success depends on delivering consistent, reliable, and fair outcomes. Testing AI is crucial to ensure models stay accurate, unbiased, and effective as data and conditions evolve. Effective testing strategies can reduce risks, enhance AI system efficiency, and increase assurance in such systems.
In this article, we will explore best strategies for testing AI models, with special focus on best practices throughout the respective development lifecycle, including data preparation, data model development, post-deployment monitoring, etc. These methods solve issues such as model drift, bias, and security risks, and you can be sure AI applications are going to work securely and efficiently in real-life situations.
Understanding the Challenges of Testing AI
Unlike conventional software, where outputs follow deterministic logic, AI models function based on probabilistic learning. This introduces several challenges:
Data Dependency
AI models are dependent on sizable datasets, and shoddy data can produce predictions that are not accurate. Bias, Inconsistent, or incomplete training data can seriously affect model performance and lead to poor decision-making. For input quality to be guaranteed, preprocessing, data augmentation, and validation are crucial.
Furthermore, to improve generalization and dependability, AI models must be evaluated using a variety of realistic datasets. For organizations to overcome data scarcity, they need to have strong data governance procedures, audit training data frequently, and use strategies like synthetic data generation.
Model Drift
As new and evolving patterns in the data are discovered over time, AI models may degrade. This occurs when the model’s predictions become less accurate as a result of modifications to the statistical properties of the input data.
Model drift can be divided into two categories: concept drift, which occurs when the relationship between the target variable and input features changes over time, and data drift, which occurs when the distribution of input data changes over time.
Businesses need to automate retraining pipelines on new datasets, employ adaptive learning strategies, and regularly monitor performance metrics to avoid model drift.
Fairness and Bias
AI systems may unintentionally pick up biases from training data, which could result in unfair judgments. Bias may result from the imbalanced dataset, the historical injustices, or faulty data labeling procedures. Unaddressed biased AI models have the potential to strengthen and sustain discrimination, especially in fields like lending, hiring, and law enforcement.
Organizations must use diverse and representative training data, perform fairness audits, and use debiasing strategies like adversarial training and algorithmic adjustments to reduce bias. For AI models to make fair and objective decisions, regular testing and observation are necessary.
Explainability
Most AI models, especially deep learning models, are “black boxes,” and their decisions are hard to interpret. This can become a hindrance to trust, regulatory compliance, and debugging.
To counter explainability, methods like SHAP (Shapley Additive Explanations) and LIME (Local Interpretable Model-agnostic Explanations) can be employed to explain model outputs. Rule-based surrogate models and feature attribution methods also assist in providing insights into how AI makes decisions.
Performance Variability
AI models may perform erratically on various datasets and in actual-world scenarios. Variability could be due to shifts in data distribution, environmental conditions, or model generalization.
To address this risk, thorough testing on a variety of datasets, domain adaptation methods, and uncertainty quantification techniques should be used to provide consistent performance across various settings.
To tackle these challenges, comprehensive testing of AI strategies is essential.
Key Strategies for Testing AI Models
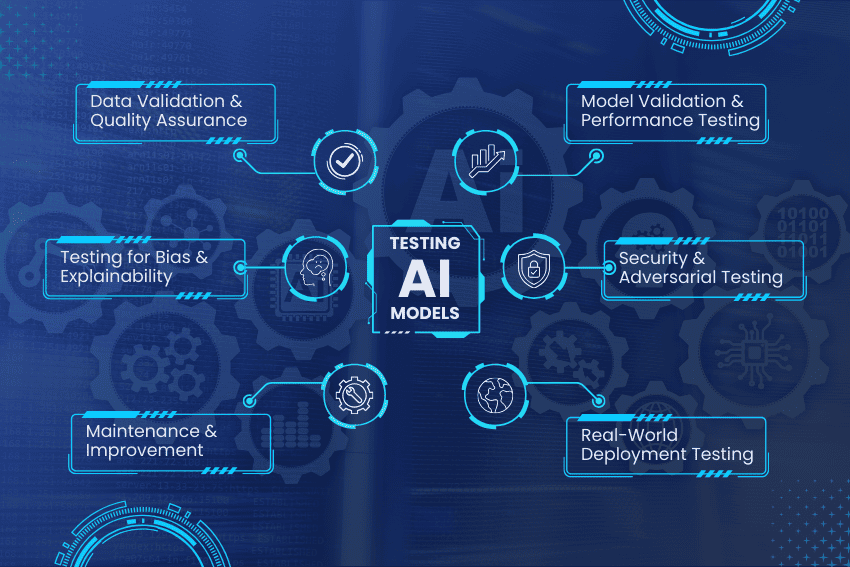
Thorough testing of AI models demands a systematic approach to deal with data integrity, model performance, fairness, and real-world applicability. Unlike other software testing, AI testing has to consider probabilistic behavior, dynamic datasets, and ethical concerns.
The following are key strategies for testing AI models that perform best under different conditions and ensure accuracy, reliability, and transparency.
Data Validation and Quality Assurance
An AI model rests on its data. It might result in poor predictions and biases, or it might even fail the production in poor quality of data. One of the first strategies is to carry out comprehensive data validation including tests of completeness, consistency, and representativeness. This involves the detection of missing elements, outliers, or skew distribution that may skew training of the model. Exploratory data analysis can be applied to visualize and identify the imbalance so that the datasets can be appropriate to the reality.
The other important point is to detect biases in the dataset. That is, the dataset should be audited before training to identify potential biases between demographic groups by measuring disparate impact or demographic similarity to achieve fairness. Such problems can be mitigated at the beginning of the task by rebalancing the dataset or using fairness-aware algorithms. Synthetic data generation using techniques such as Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs) can also be used to improve data sparsity and address data privacy and edge case coverage considerations, where no sensitive data is compromised.
The normalization and data cleaning are the methods that will aid in pre-testing the inputs and ensuring high quality. Such stage avoids garbage-in-garbage-out situations and preconditions effective models training.
Model Validation and Performance Testing
After data is ready, it is necessary to validate the model in the course of training and after it. The problems of overfitting can be addressed with iterative validation methods like the k-fold cross-validation and train-test splits which allows performance evaluation in small steps. Identify proper measures of success with respect to business objectives, e.g., accuracy, precision, recall, F1 score, AUC-ROC in the case of classification problems, and Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) in the case of regression.
Performance testing is done to check the time taken to make inferences, the latency, the throughput, and any other type of load such as a stress test and a spike test, to achieve service level agreements (SLAs). In non-deterministic your models e.g., in generative AI statistical validation through repeated testing in a controlled environment is used to separate normal variation and a problem. Early stopping of training and hyperparameter tuning also optimize the performance and prevent overfitting.
All components of the AI system work together by testing the single components individually through unit testing, the whole pipeline with integration testing, and end to end functionality with system testing. There are automated frameworks to make it reproducible by having fixed random seeds and identifying regressions, e.g., TensorFlow Model Analysis or scikit-learn utilities.
Testing for Bias, Fairness, and Explainability
Discriminatory outcomes can only be prevented through bias and fairness testing. Compare model performance based on those attributes it is not intended to predict (e.g., gender, race) with metrics such as equalized odds or disparate impact and use counterfactual examples to diagnose biases. AI can be saved, as automated bias detection tools can search through datasets and outputs and unveil subconscious biases, ensuring fair AI systems.
Explainability testing increases transparency, as it finds the interpretations of decisions made by the model. Such tools as SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) are used to identify the importance of the features and decision paths so that the predictions made correspond with known expertise and develop stakeholder trust.
Security and Adversarial Testing
AI systems are vulnerable to attacks that can control their behavior, breach data integrity, or reveal vulnerabilities. Comprehensive testing must incorporate various levels of security tests to guarantee robustness against adversarial attacks.
Adversarial attacks, in which specific inputs designed specifically for the attack are used to manipulate the model into producing wrong predictions, are one such important area. Models can be made robust against adversarial attacks using techniques like adversarial training and defensive distillation.
In addition, data poisoning tests examine if the model is susceptible to maliciously tampered training data that may cause biased or wrong results. Robustness to noisy inputs is another important point, which can facilitate the model to cope with real-world imperfections, such as corrupted or maliciously manipulated data.
Security testing should also comprise ongoing monitoring after deployment, detecting and reducing threats in real time. By combining these security measures, companies can improve the resilience of AI models, which protects against malicious attacks and makes them reliable when deployed in production.
Monitoring, Maintenance, and Continuous Improvement
Model deviations, or changes in data distribution or performance, are automatically detected by automated systems and alerting mechanisms after deployment. Measure accuracy and latency in product, and use retraining feedback loops such as shadow testing new models without interfering with production systems.
In subjective areas, human-in-the-loop (HITL) testing consists of domain experts examining outputs to verify correctness, tone and ethicality is included. Build testing into CI/CD pipelines to automatically check on the changes and control versions of data, code, and models.
Ensemble tests allow testing a number of models simultaneously to decrease variance, ethical oversight checks the effect on groups and that the tests are in line with regulations.
Real-World Deployment Testing
Before an AI model goes live, it needs to be thoroughly tested under actual use to ensure reliability, precision, and adaptability. Real-world deployment testing involves stages that examine different aspects of model behavior and user interaction. A/B testing is a key approach—comparing two model versions in real environments to identify which performs better based on real-time user behavior.
User feedback is crucial for refining accuracy, usability, and responsiveness, while edge-case testing validates model performance under rare or extreme conditions to ensure robustness. Continuous monitoring and retraining help AI systems stay aligned with evolving data patterns and avoid performance drift.
Scalability and infrastructure readiness are equally critical, especially when deploying across diverse environments. Utilizing cloud-based platforms like LambdaTest can support this phase by simulating real-world user conditions at scale, ensuring seamless integration and high efficiency across systems.
LambdaTest for Cloud Mobile Phones: Elevate Your Mobile Testing to the Cloud
LambdaTest is an AI-native test execution platform that lets you run manual and automated tests at scale across 3000+ real browsers, devices, and OS combinations.
With the rapid evolution of mobile experiences, ensuring app performance across various devices, OS versions, and network conditions can be a major challenge. LambdaTest simplifies this through its scalable cloud-based mobile testing platform, giving teams instant access to real mobile devices without the cost and complexity of maintaining a physical device lab.
Its robust suite of testing capabilities ensures your mobile apps deliver a consistent, responsive experience across different screen sizes and environments. Powered by intelligent test orchestration and automation, LambdaTest enables developers and QA teams to execute tests seamlessly in real-world conditions, accelerating releases and improving mobile quality at scale.
This is what makes LambdaTest unique:
- Real Device Access: Instantly test on 10,000+ real mobile devices and OS combinations from the cloud, no need for physical labs. Just pick a device and start testing across screen sizes and hardware types.
- Parallel Testing at Scale: Speed up test cycles by running multiple cases at once on various devices. Scalable cloud infrastructure supports both manual and automated testing for faster releases.
- AI-Powered Automation: Supports frameworks like Selenium, Appium, Espresso, and XCUITest. AI-driven insights help identify bugs faster and improve productivity.
- CI/CD Integration: Seamlessly connects with tools like Jenkins, GitHub Actions, CircleCI, and Azure DevOps to enable continuous mobile app testing before each release.
- Geolocation & Live Testing: Perform live debugging and UI/UX checks in real time on actual devices. Validate region-specific features with built-in geolocation testing.
Conclusion
Testing AI is a dynamic and iterative process that necessitates ongoing verification, equity checks, and performance evaluations in real time. Robust testing frameworks guarantee that AI models continue to be impartial and accurate, and flexible in response to shifting conditions. For organizations to identify discrepancies and improve transparency, explainability tools, fairness audits, and automated monitoring systems must be integrated.
Furthermore, it is imperative to create strong governance frameworks that include human oversight and make sure ethical considerations are ingrained throughout the AI lifecycle.
The use of AI ethics guidelines, compliance with legal requirements, and the encouragement of interdisciplinary cooperation among AI engineers, subject matter experts, and legal professionals all contribute to the reliability of AI models. By promoting a proactive approach to testing AI, businesses can minimize risks, optimize model performance, and develop trustworthy AI-driven solutions that increase user confidence and foster long-term growth.
By avoiding malfunctions, improving operational effectiveness, and fortifying regulatory compliance, a well-defined testing strategy guarantees AI will continue to offer substantial value in a rapidly evolving technological landscape.