As businesses more trust on data to inform strategies, the real cost of bad data extends greatly ahead of ordinary financial effects; it can break customer trust, hamper productivity, and stifle innovation. Understanding the difficulties of poor data quality is necessary for organizations looking to optimize their performance and ensure growth in competitive circumstances.

Digital acceleration has made businesses rely on high-quality data to stay competitive and efficient, as well as to make more informed decisions. But, are you truly cognizant of what high-quality data is? How will you tell if your data measures up?
Data is considered high quality when it can be easily processed, analyzed, and used for its intended purpose. Low-quality data (filled with inaccurate, obsolete, or inconsistent entries) can have severe consequences. It can impact your company’s finances, reputation, legal standing, and operations. Despite that, nearly 60% of businesses are unaware of the cost of bad data because they fail to track its impact. [Source].
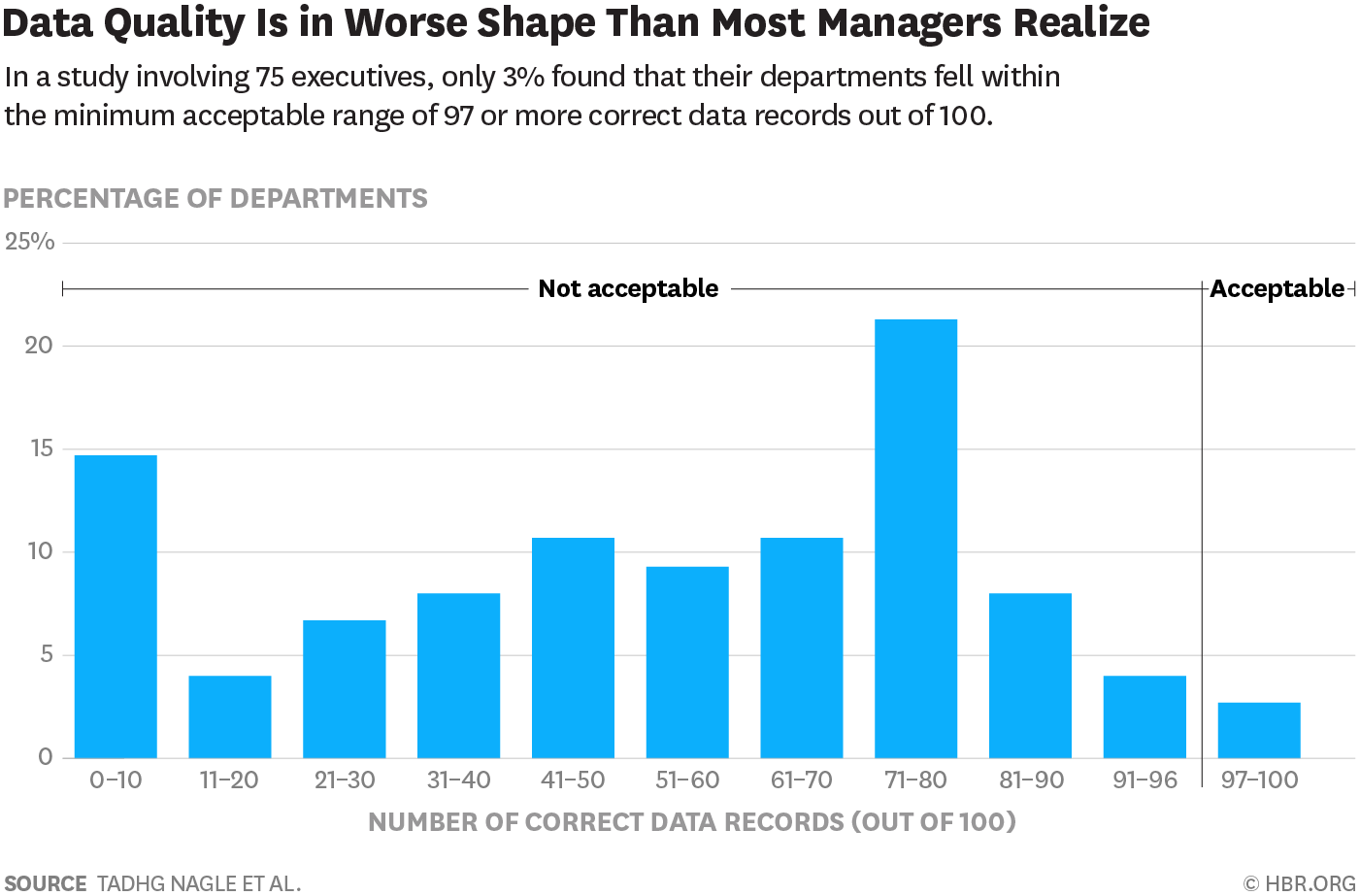
Image Source – Harvard Business Review
If you are also struggling with bad data, this is the time to understand why prioritizing data quality management is critical for your business and how neglecting it can severely affect the bottom line.
This article explores the real cost of bad data and focuses on the importance of investing in data integrity.
Culprits of Bad Data – Most Common Reasons for Quality Issues in Data
There is never a single reason for data deterioration. It’s often the result of several factors coming together. Some of the most common causes behind poor data quality include:
-
Human Error
Manual data entry mistakes, lack of training, or oversight can introduce inaccuracies, leading to unreliable datasets.
-
Integration Error
Errors can occur when converting data from one format to another to integrate into a centralized database. Take a spreadsheet, for instance—it organizes data in a neat, structured way, while a CSV uses simple commas to separate values. When you try to convert that spreadsheet into a CSV, the structured data may end up split across multiple chunks, causing inconsistencies.
-
Inadequate Standardized Processes or Data Governance
If there are no set guidelines for data collection, entry, and processing, inconsistencies are bound to happen as different departments record and manage data differently. When such datasets are integrated into a centralized system, discrepancies occur.
-
System Errors or Glitches
Technical glitches or software failures during data collection, storage, or processing can introduce inaccuracies.
The Ripple Effect: How One Error in Data Leads to Another
Any error in the business database, when left unresolved, can initiate a chain of reactions, affecting the overall bottom line of business. This statement might seem too much when read, but it can be explained well through an example:
Let’s say a retail company manages its inventory using data from multiple stores. One store incorrectly enters the product quantity for a popular item as 500 units instead of 50. This small mistake might seem harmless at first, but it creates a ripple effect.
- First, the sales & marketing team sees the inflated number and assumes they have ample stock. To promote the product heavily online, they allocate additional budget, encouraging more sales.
- As orders come in, the warehouse team realizes they only have 50 units, not 500. Now, they struggle to fulfil orders, leading to delays, customer complaints, and cancellations.
- The procurement team now steps in, ordering more stock, and tying up capital in excess inventory.
So, one small data entry error in the inventory leads to misaligned strategies across departments—marketing spends money unnecessarily, customers are frustrated, and the company’s finances take a hit. This is how a single data quality issue can snowball into bigger, more complex problems across the business, making data quality management a necessity for organizations.
How Poor Data Impact on Businesses – Real-World Examples

Image Source: Experian
As stated above, the impact of inaccurate data on businesses can be multiple. Depending upon the use cases and relevance of that data, implications can differ. Let’s understand them one by one with notable real-world examples:
Legal Implications
Any business has to follow the data privacy regulations applicable in their regions- like GDPR in the EU or CCPA in the US -to avoid being penalized. These laws are basically data governance frameworks that can protect sensitive information from leaking out. Ignoring them is equal to inviting hackers and attackers to access your data.
A good example of this instance is the 2017 Equifax data breach. Equifax is among the world’s top three consumer credit reporting agencies (also called the Big Three). It was attacked between May and July 2017. Names, social security numbers, birth dates, addresses, driver’s license numbers, credit card numbers, and certain dispute documents- such private records were leaked for 147.9 million Americans, 15.2 million British citizens, and about 19,000 Canadian citizens. While the reason turned out to be a large backlog of vulnerabilities that Equifax simply overlooked, the cost to the company was a settlement of $425 million— making it one of the largest settlements in response to an identity theft or data breach [Source].
Financial Loss
Revenue loss is one of the most prominent impacts of poor data. Studies have suggested that financial loss to an organization due to inaccurate or bad data can be around $12.9 million annually [Gartner]. This financial loss can be due to wasted resources, low productivity, loss of potential clients or opportunities, or collectively all of them.
One prime example of how a simple data entry error can lead to significant revenue loss is Samsung Securities’ Fat Finger Error. The company was paying dividends to about 2000 employees who were a part of the company stock ownership program. However, one of the responsible employees mistakenly entered two billion “shares” where he was supposed to enter two billion “Won” (as in South Koran Won). As a result, shares worth nearly 112.6 trillion won, which happened to be thirty times the company’s market capitalization at the time, were issued. The company caught this error, but it took 37 minutes, unfortunately. In that time, sixteen employees had already sold their shares, which caused an 11% drop in their stock within a day.
Operational Paralysis
When the data is inaccurate, obsolete, or inconsistent, it demands a significant amount of professionals’ time to identify the errors and correct them. According to ResearchGate, data scientists spend about 60% of their time on data cleansing and organization and only 9% on analyzing it for critical business insights. This inefficient allocation of resources not only leads to operational slowdowns but also impacts overall productivity. Instead of driving innovation or deriving critical insights for business growth, highly skilled professionals are forced to wrestle with data accuracy.
Data Integration Barriers
Different systems collect and store information in various formats, leading to inconsistencies in data structure. When merging such datasets, integration challenges arise. For example, if one system records dates using the format MM/DD/YYYY (10-28-2024) and another uses DD/MM/YYYY (28-10-2024), merging both datasets will throw a challenge.
In addition, incomplete or inaccurate data can further complicate integration efforts. When one system provides missing or incorrect information, the entire data pipeline becomes unreliable, leading to gaps or incorrect matches between records. This reduces the overall quality and reliability of the integrated data.
We see these issues mostly in industries like healthcare, where multiple stakeholders (such as hospitals, regulatory agencies, and insurance companies) use different systems to manage patient data at their end. This was also highlighted as a significant challenge in a recent interview with Friederike von Krosigk, Chief Strategy & Marketing Officer at GE Healthcare (an American medical technology company). She pointed out how diverse data systems make it difficult to maintain interoperability and data accuracy, as well as how straining it is to merge them.
Brand Reputation Damage Risks
Data errors or quality issues not only lead to financial or legal consequences. In all of the above-stated examples, we have witnessed how poor data also affects brand reputation. When you make decisions on faulty or inaccurate data, it impacts the bottom line of your business. This leads to brand reputation damage as customers lose their trust in your brand. This can be explained better through the real-world example of Unity Technologies’ ad targeting error.
This renowned real-time 3D content platform offers a service called Unity Ads, allowing developers to monetize their apps and games by integrating ads. The platform relies heavily on data to target users with relevant ads, ensuring advertisers reach the right audience while developers maximize revenue.
However, the bad data ingestion caused the ad targeting algorithm to misinterpret user information. This resulted in ads being displayed to the wrong audience segments. Due to poorly targeted ads, the advertisers saw a significant reduction in the campaigns’ ROI. This led to a loss of trust in Unity’s ad-serving capabilities, with some advertisers opting to pull their campaigns or shift to other platforms.
This sudden shift took a direct hit on Unity’s revenue-sharing platform, leading to a loss of $110 million. Not only the advertisers but also the stakeholders lost their trust in the company’s offerings, resulting in a significant drop (37%) in its shares.
Opportunity Loss
Poor data quality will hurt your sales and marketing efforts. It will lead to missed opportunities that directly impact growth and revenue. That is certain!
Let’s try to understand this with examples. A sales team that uses incomplete, incorrect, or old data will never be able to identify and target the right potential customers. Ergo, their lead generation efforts will suffer. A marketing team using obsolete information about the target audience will waste valuable time and resources trying to reach out to people who are simply not interested.
Meanwhile, your competitors will get the chance to nurture leads that you have missed.
So, in essence, if you burden your sales pipeline with unreliable data, you will struggle to convert prospects into paying customers. And the drawbacks don’t stop there. Your team won’t be able to track market trends or grasp the shifts in consumer behavior. Taking advantage of new opportunities will be impossible because you won’t be able to identify them in the first place.
Effective Strategies for Data Quality Management
To operate at its best, businesses need to prioritize efficient data management practices. However, it is not a “set it and forget it” task. Maintaining data quality and integrity is an ongoing process that demands dedicated professionals, advanced infrastructure, and time. Three ways you can integrate data quality management into your workflow are:
Implement a Data Governance Framework In-House
To have complete control over your data, one of the best practices is to establish a robust governance framework in-house. It is the first and foremost step to ensure that data is collected, processed, stored, and retrieved by various teams ethically and securely.
- Define roles, responsibilities, and accountability for data management. Each department should have designated data stewards who act as gatekeepers, ensuring that data quality is upheld and used appropriately.
- Create detailed data standards and policies to guide how data should be collected, stored, managed, and accessed. These policies should cover everything from data formatting to privacy regulations, ensuring compliance with industry standards like GDPR or CCPA.
- Monitor the effectiveness of the data governance framework once it is in place. Through regular audits, identify areas for improvement and make the required changes to enhance data quality management.
Utilize Augmented Data Quality Management Solutions
Not leveraging AI and ML technologies to keep big data accurate, reliable, complete, and recent can be a disadvantage for businesses in this tech-driven era. While technology can’t replace human intelligence, it certainly makes the data management process easier and faster by automating several aspects, such as error identification, data deduplication, and cleansing. Other important tasks, such as data enrichment and validation, still demand subject matter expertise.
To automate these processes, some of the augmented data quality management solutions you can leverage are:
- Data Profiling Tools
Platforms like IBM Infosphere Information Analyzer, Atlan, and Data Ladder help you examine the data from existing sources and understand its structure. By assessing the data’s characteristics, they highlight possible inconsistencies and errors (such as missing values, duplicates, and incomplete details) to give you a complete picture of your database’s health. Additionally, they help prioritize which problems need fixing at the source and which can be addressed later.
- Data Integration Tools
To overcome the integration challenges, tools like Talent, Microsoft SSIS, and Apache NiFi can be helpful. These tools automate data conversion and manage the quality of data during the integration process.
- Data Lineage Tools
For tracing the journey of your data and understanding its transformation at each stage, platforms like Collibra, MANTA, IBM, and InfoSphere Information Governance Catalog can be helpful. By offering a clear view of your data’s path, they help identify at which stage inconsistencies originate so you can fix them to avoid future instances.
- Data Processing Tools
AI-powered platforms like Trifacta, Talend, Informatica, and Data Ladder are widely used by organizations to identify inconsistencies & errors in data and automate data deduplication and cleansing for quality management.
Outsource Data Management Services to a Trusted Provider
For budget or resource-constraint organizations, the above two approaches can be less effective than outsourcing. Partnering with a reliable third-party provider for data management services can be beneficial for businesses as they don’t have to invest in experienced professionals or advanced infrastructure. With access to the latest tools and a team of experts, these providers handle every aspect—data cleansing, enrichment, validation—ensuring your data remains accurate, actionable, and up-to-date.
Key Takeaway
Poor quality data doesn’t just slow down your business – it can completely undermine your growth efforts. Every decision based on inaccurate or incomplete information costs you opportunities, resources, and potential revenue. By prioritizing data quality now—whether through improved in-house data management processes or by outsourcing to experts—you’re not just cleaning up your spreadsheets; you’re clearing the path for sustainable business growth. The future belongs to organizations that are data-driven, and to get there, it’s time to say no to the bad data and make room for structured, reliable, and ready-to-analyze datasets that propel your business forward.


